Rosie Sherry
CEO & Founder at Ministry of Testing
She/Her
I am Open to Speak, Meet at MoTaCon 2026, Write, Mentor, CV Reviews, Podcasting, Teach
I've been working in the software testing and quality engineering space since the year 2000 whilst also combining it with my love for education and community. It turns out quality, community and education go nicely hand in hand.
🎓 MoT-STEC qualified
Achievements

























































Certificates

Awarded for:
Passing the exam with a score of 100%

Awarded for:
Achieving one or more Community Stars in five or more unique months
Activity

thanked contributors on:
First public outing of pixelmesh v2 at the Manchester chapter evening last night.
What looks simple on the surface, phones flashing in sync, is actually computer vision, distributed systems, synchr...
earned:
Manchester chapter evening
awarded Adam Davis for:

Manchester chapter evening
awarded Matillion for:

Manchester chapter evening
awarded Darryl Kennedy for:

Manchester chapter evening
Contributions

The sense of loss will be outweighed with the joy of influence


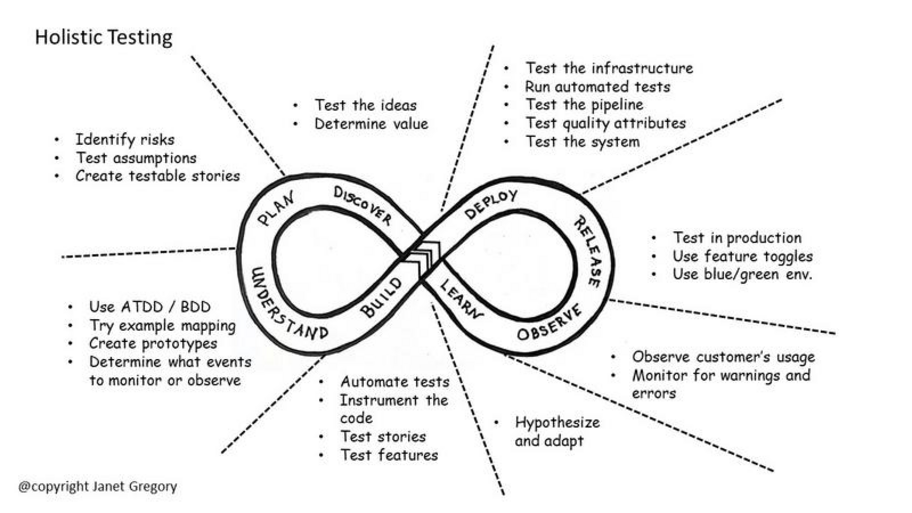
What is Holistic Testing? The Holistic Testing model, developed by Janet Gregory and Lisa Crispin, maps testing activity across every stage of an infinite development loop: discover, plan, underst...
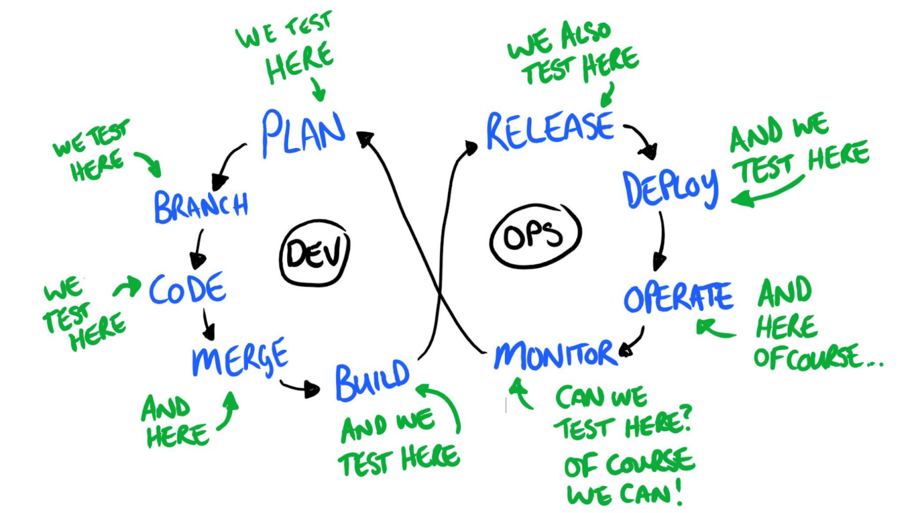
Back in 2016, Dan Ashby wrote about the Continuous Testing Model, which emphasises the ability to test at every stage of the software development lifecycle.
What is The Continous Testing Model? Da...

Also, prompt your way to MoTaCon 🖖

Matthias writes about design and engineering as one, (it's a great read) and how in 1898, Frederick Winslow Taylor's answer to inefficiency was to separate the work that people did. Those who did t...



Vulnpocalypse the moment when language models can find zero-days and write working exploits faster than we can patch them.
Vulnpocalypse. We use it to describe the inflection point where LLMs are able to discover zero day vulnerabilities, and create zero day exploits, faster than we can patch.

An active and high-severity, real-world attack that deploys a zero-day exploit against targets before a patch is available. Because no fix exists, standard defences such as software updates offer no protection. Zero-day attacks are particularly dangerous in critical infrastructure, government systems, and enterprise environments.
State-sponsored actors using the browser exploit to silently install surveillance software on journalists' devices, undetected, and with no defence available to victims, constitutes a zero-day attack.
