Testing with feature flags: what we expected and what actually happened
Feature flags entered our workflow as a quality safeguard.

Feature flags, sometimes called feature toggles, allow teams to enable or disable specific functionality in an application without deploying new code. They are often used alongside CI / CD workflows to control when features become available to the end user without requiring a new release. In our case, though, feature flags were mostly managed manually across environments, which made their state harder to track. But we adopted them anyway because they promised safer releases, controlled rollouts, and fewer last-minute rollbacks.
From a delivery perspective, testing with feature flags felt like a clear improvement. The engineering team could deploy code without immediately exposing it to users, separating deployment from release, and the QA team could be less stressed about potential bugs. But from a testing perspective, the picture turned out to be more nuanced.
Over time, I realised that turning a feature off via a feature flag didn’t mean "risk removed". The code was already deployed, the logic already wired in, and the E2E tests written by the QA automation team were not always exercising the behaviour users would eventually experience.
This article isn’t about whether feature flags are good or bad. It’s about how they quietly reshaped my testing strategy, challenged our assumptions, and forced my team to rethink what "done" really means in a feature-flagged system.
But first, what exactly are feature flags?
At a basic level, a feature flag acts as a conditional switch. The code for a feature can be deployed to production or any other environment, but its visibility or behaviour is controlled by configuration in a specific system. By changing the flag’s state, teams can turn the feature on or off instantly, often for specific users, environments, or percentage-based rollouts. This can make the testing process much clearer and easier.
Our team has used Split.io for feature flagging, but this article isn’t about that platform. We use feature flags to reduce release risk, experiment safely, and separate deployment from release. They allow unfinished features to be deployed to production without being exposed, support gradual rollouts, and provide a quick rollback mechanism without redeployment.
You may hear people on your teams talk about testing "behind" feature flags. It simply means that feature flags are being used. I use that term frequently in this article.
Why did feature flags look to us like a quality win?
Our context
Our engineering team introduced feature flags to reduce release pressure and increase flexibility as the system and team scaled. They allowed developers to merge code earlier in the development cycle, eliminate branches that had outlived their utility, and control exposure without emergency rollbacks. From a quality assurance standpoint, this initially felt like progress. Fewer risky releases, more time to test, more control.
What this looked like in practice
Features were tested behind disabled feature flags. Once the tests passed, the code was deployed and considered "safe," and enabling the flag later was treated as a controlled, low-risk step.
What we learned after adopting feature flags
What I hadn't realized at that time was that, in the feature flags process, the risk still exists. It's not obvious, but it's distributed. The moment of risk shifts from deployment to enablement, and unless testing strategies shift with it, gaps begin to appear in places I am not actively validating.
How did feature flags change the test environment?
Our context
With feature flags in place, the system stopped being binary. Behaviour became conditional, depending on flag states rather than on just deployed code.
What this looked like in practice
In practice, this meant I was no longer testing a single version of the system. Now I had multiple states to consider:
- Code deployed with the flag off
- The feature is enabled for only certain groups of users
- Partial rollouts
- Interactions between multiple active flags
Each flag multiplied the number of possible behaviours. Tests that passed in one configuration no longer guaranteed safety in another.
Automation suites validated happy paths, but often only in a single-flag state. Environments drifted because flags were toggled differently in staging and production. Behaviour became conditional and often invisible.
What we learned
Test coverage started to look better than it actually was. I had confidence, but it was confidence built on incomplete system states and limited visibility into real user scenarios.
Feature flags expand the test surface. If that expansion is not acknowledged explicitly in testing strategy, gaps appear quietly and often only surface later in production.
A defect I didn’t catch until we turned on a feature flag
Our context
One feature was thoroughly tested behind a disabled flag. The feature was responsible for processing and displaying a subset of user-related data under specific conditions. Functional tests passed. Regression tests were green. The release felt safe.
What happened
When the flag was enabled for a limited group of users, an issue surfaced. A background process was always active, even when the flag was off. It interacted with existing data in a way that only became visible once the feature was enabled. From a testing perspective, everything I validated was correct. But from an end-user perspective, the experience was broken the moment the feature was enabled.
What we learned
The issue wasn’t caused by missing tests. It was caused by a false assumption: that "disabled" meant "inactive," while parts of the system that involved the feature were already running in the background.
Feature flags can hide side effects. Code paths may exist, run, and influence the system long before a feature is visible to users, making some risks effectively invisible to traditional testing approaches.
What testers had to rethink
Our context
After encountering similar patterns, it became clear that our existing approach wasn’t sufficient.
What changed
I had to rethink several aspects of our testing strategy:
- Treating "flag ON" as a first-class test state, not a post-release concern
- Explicitly documenting expected flag configurations per environment
- Involving the tester earlier in discussions about flag scope and lifetime
- Actively participating in rollout decisions, not just validating outcomes
- Challenging the assumption that flags are temporary (they rarely are)
One of the most important changes was making feature flag states visible across teams. As our system grew and multiple squads started managing their own product areas, feature flag visibility became a real challenge. With six squads working in parallel, each owning different parts of the product, it became increasingly difficult to understand which flags were enabled, where, and under what conditions.
To fix this, I introduced a shared feature flag tracker. The goal was simple: make feature flag states visible across environments and teams. That’s why I created a lightweight table that captured all the data the team needed to know:
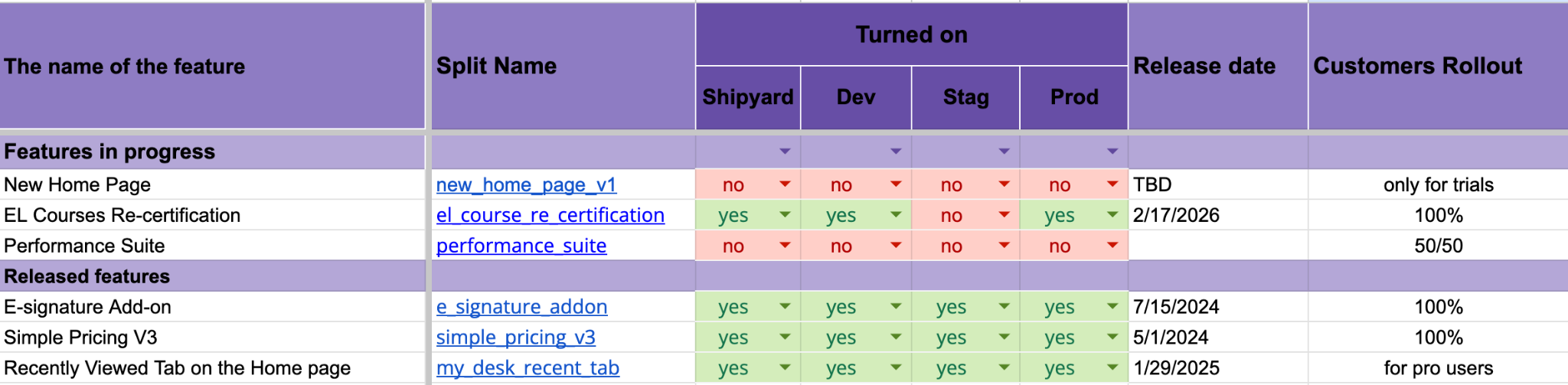
The table above contains the following information:
- “The name of the feature” column refers to the product functionality behind the flag.
- “Split name” is the identifier of the feature flag used. It’s usually a live link to the flag in the system, and it simplifies the search time.
- “Turned on” shows whether the flag is enabled in each environment (dev, staging, production).
- “Release date” indicates when the feature is planned to be released or has already been released.
- “Customers rollout” describes how the feature is exposed to users (limited rollout, percentage-based, or fully enabled).
What we learned
After we started tracking the flags, testing became more predictable. I could quickly identify mismatches between environments, understand which features were actually active in production, and avoid testing against incorrect assumptions.
It also improved collaboration. Conversations about feature flags became clearer because everyone was working with the same visibility, rather than relying on implicit knowledge or assumptions. I also started our QA Weekly meetings by reviewing this spreadsheet first to make sure the information was still accurate.
Feature flags don’t just simply add to the configuration. They also add complexity that needs to be managed explicitly. Without visibility, testing decisions become guesswork. What seems like a safe or controlled release can still hide unexpected behaviour if the actual system state is not fully understood. Making feature flag states visible turned out to be as important as testing the feature itself.
Feature flags: trade-offs, not pros and cons
From a quality assurance perspective, feature flags bring real benefits, especially when teams are trying to balance speed and control in their release process:
- Safer deployments
- Better rollback options
- Controlled exposure
However, these benefits come with trade-offs that are not always immediately visible:
- Increased test complexity
- Hidden logic paths
- Environment drift
- False confidence when tests cover only disabled states
In practice, these trade-offs don’t appear all at once. They accumulate over time, especially as more flags are introduced and remain in the system longer than expected.
None of these is a reason to avoid feature flags. But they ARE reasons to be more intentional about how we design, simplify management for the QA team, and test the systems that rely on them.
Using feature flags in the long term
Feature flags are often introduced as temporary solutions. In practice, many of them remain in the system far longer than originally intended. Over time, flags become part of the system’s behaviour rather than a short-lived release mechanism. They introduce additional branches in logic, increase the number of possible system states, and make reasoning about behaviour more complex.
From a testing perspective, this creates a long-term impact. Each persistent flag adds to the number of scenarios that need to be considered, even if the feature itself is no longer actively changing. This is where feature flags start to intersect with technical debt. When flags are not actively managed, cleaned up, or clearly owned, they accumulate. The system becomes harder to understand, harder to test, and more prone to hidden interactions between features.
In our case, this led to introducing a simple lifecycle approach for feature flags. I started treating flags as entities that need ownership, visibility, and eventual removal. I introduced a simple process for reviewing and deprecating flags that were no longer needed. Testers became actively involved in this process, helping identify flags that were no longer adding value but still increasing system complexity.
To support this, I made the lifecycle of feature flags visible by tracking their deprecation status and expected removal timeline.
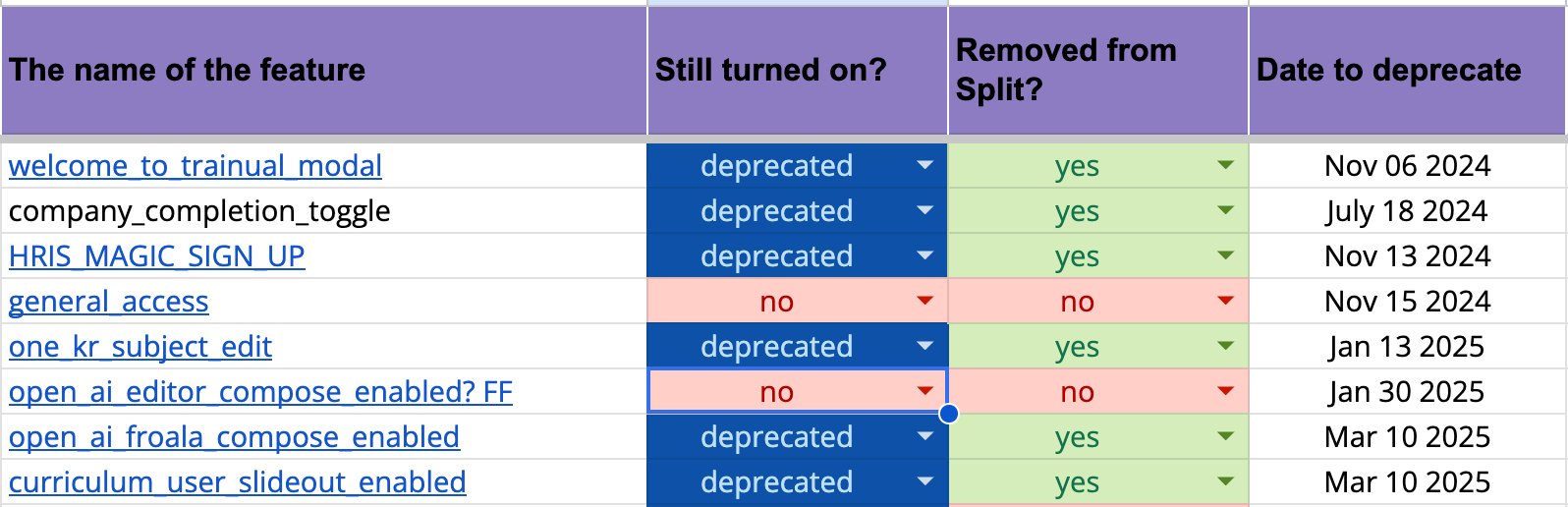
The table above contains the following columns:
- “The name of the feature” column refers to the functionality behind the flag.
- “Still turned on?” shows whether the flag is still active or already deprecated.
- “Removed from Split?” indicates whether the flag has been removed from the feature flag system.
- “Date to deprecate” shows when the flag is expected to be fully removed.
This tracking method helped us start treating feature flags as temporary by design, rather than letting them silently become permanent.
What we learned
Feature flags are not just a release tool. They are also part of the system architecture, and without active management, they contribute to long-term complexity and technical debt.
To sum up: what this changed in my testing mindset
Working with feature flags changed how I think about quality management. Instead of asking, "Is the feature tested?", I now ask, "Which system states have we actually validated?" Instead of assuming safety based on deployment success, I look for clarity around enablement, configuration, and interaction.
Feature flags taught me that quality risk does not disappear. It simply moves. Unless testing strategies move with it, gaps will eventually surface where users find them first.
Key takeaways
- A disabled feature flag does not mean inactive logic.
- Feature flags expand the test surface, often invisibly.
- "Flag ON" deserves the same testing focus as "feature complete."
- The test engineer should be involved in feature flag design, not just test execution.
What do YOU think?
Feature flags are often introduced as a delivery or engineering solution, but their impact on testing is not always obvious at first. If you work with feature flags in your product, I’d love to hear how they’ve shaped your testing approach, for better or worse. Use the questions below as a starting point for reflection and discussion.
Questions to discuss
- How do you decide which feature flag states are critical to test?
- Do your environments reflect real production configurations?
- How often do "temporary" flags become permanent?
- What assumptions do you make when a feature is hidden?
Actions to take
- Review one feature tested behind a flag and list all possible states.
- Enable the flag in a controlled environment and rerun critical scenarios.
- Document flag ownership and expected lifetimes.
- Treat feature flag logic as production logic, not scaffolding.
For more information

Head of QA with 11+ years of experience in building QA processes, leading teams, and driving test automation. Passionate about AI in QA, process optimization, and leadership in quality.
Comments







